- Találatok: 3687
A Kárpát-medencei magyar nyelvi korpusz
A Kárpát-medencei magyar nyelvi korpusz a magyar nyelv legkiegyensúlyozottabb számítógépes nyelvi adatbázisa: anyagát a magyar nyelv öt regisztere alkotja (sajtó, szépirodalom, tudományos próza, hivatalos nyelv és személyes közlések). A korpusz sajátossága, hogy szövegei között nem csak a magyarországi nyelvváltozatokat, hanem a Magyarországgal szomszédos országok közül a szlovákiai, romániai, ukrajnai és szerbiai magyar nyelvváltozatokat is tartalmazza. A határon túli alkorpusz nem kíván a határon túli magyar szövegek reprezentatív mintája lenni, hiszen a reprezentativitás kritériumait ez esetben lehetetlen lenne megfogalmazni, s ha ezek a követelmények megfogalmazódnának is, az egyes szövegtípusok állandó változását, az egyes arányok mozgását szinte lehetetlen lenne követni.
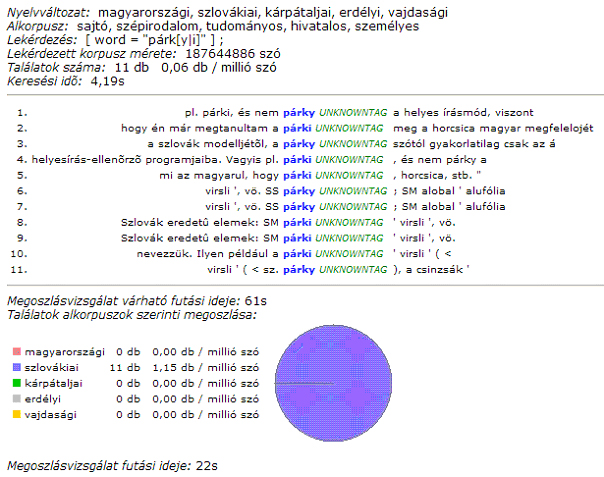
A határon túli magyar korpuszban a határon túli magyar nyelvű anyagok aránya a következőképpen lett meghatározva: szlovákiai magyar rész 4 millió, a romániai 6 millió, a kárpátaljai 3 millió, míg a vajdasági 2 millió szövegszó. A Kárpát-medencei magyar nyelvi korpusz elődjeként működő Magyar nyelvi szövegtár is tartalmazott határon túli szövegeket, mégpedig szlovákiai és romániai magyar napilapokat (a szlovákiai Új Szót és a romániai Magyar Szót), amelyek a kiegészülés után a kisebbségi sajtóhoz lettek csoportosítva. Ezt természetesen akkor csupán mutatványként vagy jó szándékként lehetett értelmezni, ami a szókereséskor inkább zavaró volt, mint segítő, hiszen a nem magyarországi sajtóban külön nem lehet keresni, viszont a magyarországi adatok keresése közben a határon túli adatok zavaróak voltak. Nyilvánvaló volt tehát, hogy szükség és igény van egy nagyobb, a kisebbségi magyar nyelvváltozatokat bemutató szövegtárra is. A határon túli magyar nyelvváltozatokat bemutató korpusz része a Termini Kutatóhálózat egyik fő feladataként aposztrofált határtalanításnak, hiszen a szövegtár célja a határon túli magyar nyelvváltozatok magyarországi terjesztése.
A Kárpát-medencei magyar nyelvi korpusz határon túli anyaga remélhetőleg a továbbiakban bővülni fog: mégpedig nem csak mélységében, hanem szélességében is. Remélhetőleg sikerül majd őrvidéki és muravidéki anyagokat is gyűjteni, illetve feldolgozni.
A Kárpát-medencei magyar nyelvi korpusz jelenlegi állapota a következő (2007. október 1-jei állapot):
|
|
magyarországi |
szlovákiai |
kárpátaljai |
erdélyi |
vajdasági |
összesen |
|
sajtó |
71,0 |
5,7 |
0,7 |
5,5 |
1,5 |
84,5 |
|
szépirodalom |
35,3 |
1,4 |
0,4 |
0,8 |
0,2 |
38,2 |
|
tudományos |
20,5 |
2,3 |
0,7 |
1,6 |
0,3 |
25,5 |
|
hivatalos |
19,9 |
0,2 |
0,3 |
0,6 |
0,1 |
20,9 |
|
személyes |
17,8 |
— |
0,4 |
0,4 |
0,1 |
18,6 |
|
összesen |
164,7 |
9,5 |
2,5 |
8,9 |
2,0 |
187,6 |
(forrás: http://corpus.nytud.hu/mnsz/bevezeto_hun.html)