A magyar nyelv számítógépes szövegtárai közül az egyik legnagyobb az MTA Nyelvtudományi Intézetében szerkesztett Kárpát-medencei magyar nyelvi korpusz. Mérete mellett másik kiemelkedő sajátossága – és egyben egyedisége is –, hogy a magyar nyelvet nemcsak mint a magyarországi beszélőközösség által használt nyelvváltozatok együttesét, hanem mint a Kárpát-medencei magyarság sajátját mutatja be. A magyarországi magyar nyelvváltozatok mellett a határon túli magyar nyelvváltozatokból is, pontosabban a romániai, szlovákiai, ukrajnai és szerbiai magyar nyelvváltozatokból tartalmaz szövegeket, amelyek külön vagy az egész korpusz szerves részeként lekérdezhetőek:
A Magyar Tudományos Akadémia Etnikai-kisebbségkutató Intézetének, valamint a Magyar Tudományos Akadémia Nyelvtudományi Intézetének Nyelvtechnológiai Osztályának szervezésében, illetve az NKFP 5/044/2002 pályázatának támogatásával mintegy háromévnyi gyűjtés és feldolgozás után 2005. novemb0er 22-én, a Magyar Tudomány Napja alkalmából rendezett előadássorozat keretén belül mutatták be a Kárpát-medencei magyar nyelvi korpusz határon túli alkorpuszát. A munkálatok eredményeképpen több, mint 15 millió szóval bővült a Kárpát-medencei magyar nyelvi korpusz írott és beszélt nyelvi alkorpusza. Ez a szómennyiség, illetve a már elkészített szövegtár szóanyaga a következőképpen oszlik meg:
|
|
magyarországi |
szlovákiai |
kárpátaljai |
erdélyi |
vajdasági |
összesen |
|
sajtó |
71,0 |
5,7 |
0,7 |
5,5 |
1,5 |
84,5 |
|
szépirodalom |
35,3 |
1,4 |
0,4 |
0,8 |
0,2 |
38,2 |
|
tudományos |
20,5 |
2,3 |
0,7 |
1,6 |
0,3 |
25,5 |
|
hivatalos |
19,9 |
0,2 |
0,3 |
0,6 |
0,1 |
20,9 |
|
személyes |
17,8 |
— |
0,4 |
0,4 |
0,1 |
18,6 |
|
összesen |
164,7 |
9,5 |
2,5 |
8,9 |
2,0 |
187,6 |
(http://corpus.nytud.hu/mnsz/bevezeto_hun.html
- október 1-jei állapot)
A határon túli alkorpusz készítésének előzménye a Magyar nemzetei szövegtárig nyúlik vissza. A Kárpát-medencei magyar nyelvi korpusz megvalósítását (és így a határon túli magyar korpusz megvalósítását is) ugyanis megelőzte a Magyar nemzeti szövegtár projektje. Az akkor még 140 millió szavas korpusz pár millió szava származott határon túli folyóiratokból (a felvidéki Új Szóból és az erdélyi Romániai Magyar Szóból). Ezt természetesen akkor csupán mutatványként vagy jó szándékként lehetett értelmezni, ami a szókereséskor inkább zavaró volt, mint segítő, hiszen a nem magyarországi sajtóban külön nem lehet keresni, viszont a magyarországi adatok keresése közben a határon túli adatok zavaróan hatottak. Nyilvánvaló volt tehát, hogy szükség és igény van egy nagyobb, a kisebbségi magyar nyelvváltozatokat bemutató szövegtárra is, amelyben kereséskor a magyarországi és határon túli nyelvváltozatok egyértelműen elkülönülnek. Ez a határon túli magyar nyelvváltozatokat bemutató korpusz része a Termini Kutatóhálózat egyik fő feladataként aposztrofált határtalanításnak, mely célja a Magyarországra centralizált magyar nyelvi szó- és szövegtárak, valamint az ezekből készült nyelvtanok és egyéb kézikönyvek nyelvi anyagának határon túli magyar nyelvváltozatok elemeivel történő kiterjesztése.
Valójában mire használható ez a korpusz? A keresés eredményeképpen megkapott ún. konkordancialisták, valamint a vertikális nyelvváltozatok közötti megoszlás alapján elérhetőek a lekérdezett szóalak (vagy szótő) előfordulási különbségei. Már csak ezzel a lépéssel is feloldható a különböző nyelvváltozatok közti különbségek és azonosságok empirikus vizsgálatokon alapuló mérésének lehetetlensége (sajnos a korpuszok különböző méretéből adódó bizonyos fokú torzítás jelenleg még nem kiküszöbölhető). Ennek személtetésére – mindenféle értelmezési magyarázat nélkül – álljon itt két példa:
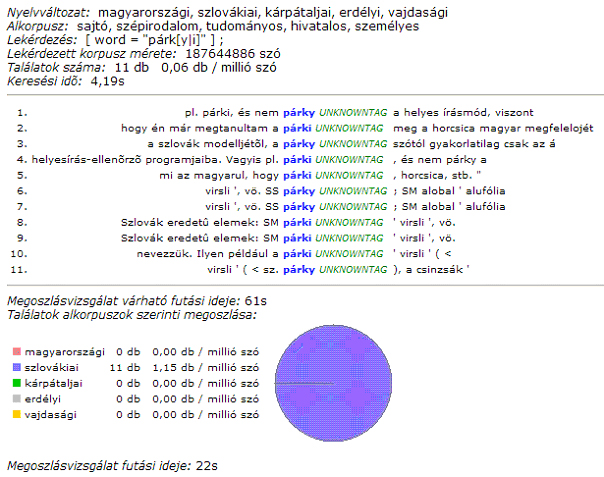
A konkordancialistákat nézve feltűnik, hogy a kék színnel jelölt keresett szóalak mellett ott található annak morfológiai tulajdonságait tartalmazó (zöld színnel jelölt) kódja. A párky szót sajnos nem ismerte fel a nyelvi elemző (ezt jelzi az „unknowtag” kód), az internátus esetében azonban többféle morfológiai tulajdonságot is láthatunk (a lekérdezésben az „internátus + bármilyen toldalék” alakot kerestük). A találati lista utáni megoszlásvizsgálatot a keresés indítása előtt az „Alkorpuszok szerinti megoszlás” kapcsoló megjelölésével opcióként kérhetjük.

A párky/párki esete azt is illusztrálja, hogy éppen a korpusz egyik kucsfontosságú pontjaként értelmezett határon túli szavak még nem elemezhetőek – a korpusz nyelvi elemzőjeként működő Humor program szótárában ugyanis ezek a szavak nem találhatók meg. Ezt a problémát úgy próbáljuk áthidalni, hogy elkészítjük és morfológiailag kódoljuk a határon túli magyar nyelvváltozatok speciális elemeit (erről bővebben a Wordject-project menüpont alatt olvashat).
2005-ben elkészült egy maga nemében egyedülálló korpusz: belső szerkezetének strukturáltsága és nyelvváltozatainak rendszere a Kárpát-medencei magyar nyelvi korpuszt nemcsak a magyar nyelvet feldolgozó korpuszok, hanem más nyelvek korpuszai között is különlegessé teszi.